Fault-Tolerant Key-Value Store
May 5, 2025 · 4 min readIntroduction
I implemented a highly-available, sharded key/value service from scratch with many shard groups for scalability, reconfiguration to handle changes in load, and with a fault-tolerant controller in Go and Python. Here, I document each step of the design process. My code is available online at github.com/kavnwang/distributed-kv-store.
Raft
At the core of my system is a Raft library that implements leader election, log replication, persistence, and snapshots. Each server cycles among follower, candidate, and leader states under a randomized election timeout. When a follower times out without receiving a heartbeat, it increments its currentTerm, votes for itself, and solicits votes via RequestVote. A voter grants a vote only if the candidate’s log is “at least as up to date,” which I check by lexicographic comparison of (lastLogTerm, lastLogIndex). The leader sends periodic AppendEntries heartbeats that also carry log entries. A follower accepts an append only if it finds log[prevLogIndex].term == prevLogTerm; otherwise it rejects and I backtrack the leader’s nextIndex[f] for that follower (using the conflict-term/first-index hint when available, otherwise decrementing).
The leader advances commitIndex using Raft’s commit rule: it finds the largest N such that a majority have matchIndex[i] ≥ N and log[N].term == currentTerm, then commits up to N. A single applier goroutine advances lastApplied and emits ApplyMsg records (entries or snapshots) on an applyCh. I persist currentTerm, votedFor, log, and snapshot metadata (lastIncludedIndex, lastIncludedTerm) so that crash/recovery never violates Raft’s safety.
KV-Raft Service
On top of Raft I built a linearizable key/value service (KV-Raft). Clients issue Get, Put, and Append RPCs containing (clientId, requestSeq). Every request—reads included—becomes a Raft log entry so that the service replies only after the command is committed and applied, which gives linearizability without special read paths. The server thread that receives a client RPC calls Start(op) on Raft, gets (index, term, isLeader), and, if leader, waits on a per-index condition channel until the applier delivers the matching result (and verifies that the term is unchanged to avoid replying based on a stale leadership).
To achieve at-most-once semantics across retries and leadership changes, my state machine keeps a dedup table lastSeq[clientId] -> (seq, lastReply). When applying a command whose seq is ≤ the recorded one, I treat it as a duplicate and return the memoized reply. To cap log growth, the KV layer triggers snapshots when raftStateSize exceeds a threshold; the snapshot serializes the KV map and the dedup table at a specific lastApplied index and calls Raft.Snapshot(lastApplied, snapshotBytes). On restart or when a follower is far behind, the leader uses InstallSnapshot to bring it forward; the service installs snapshots by replacing state and setting lastApplied = lastIncludedIndex.
Sharding
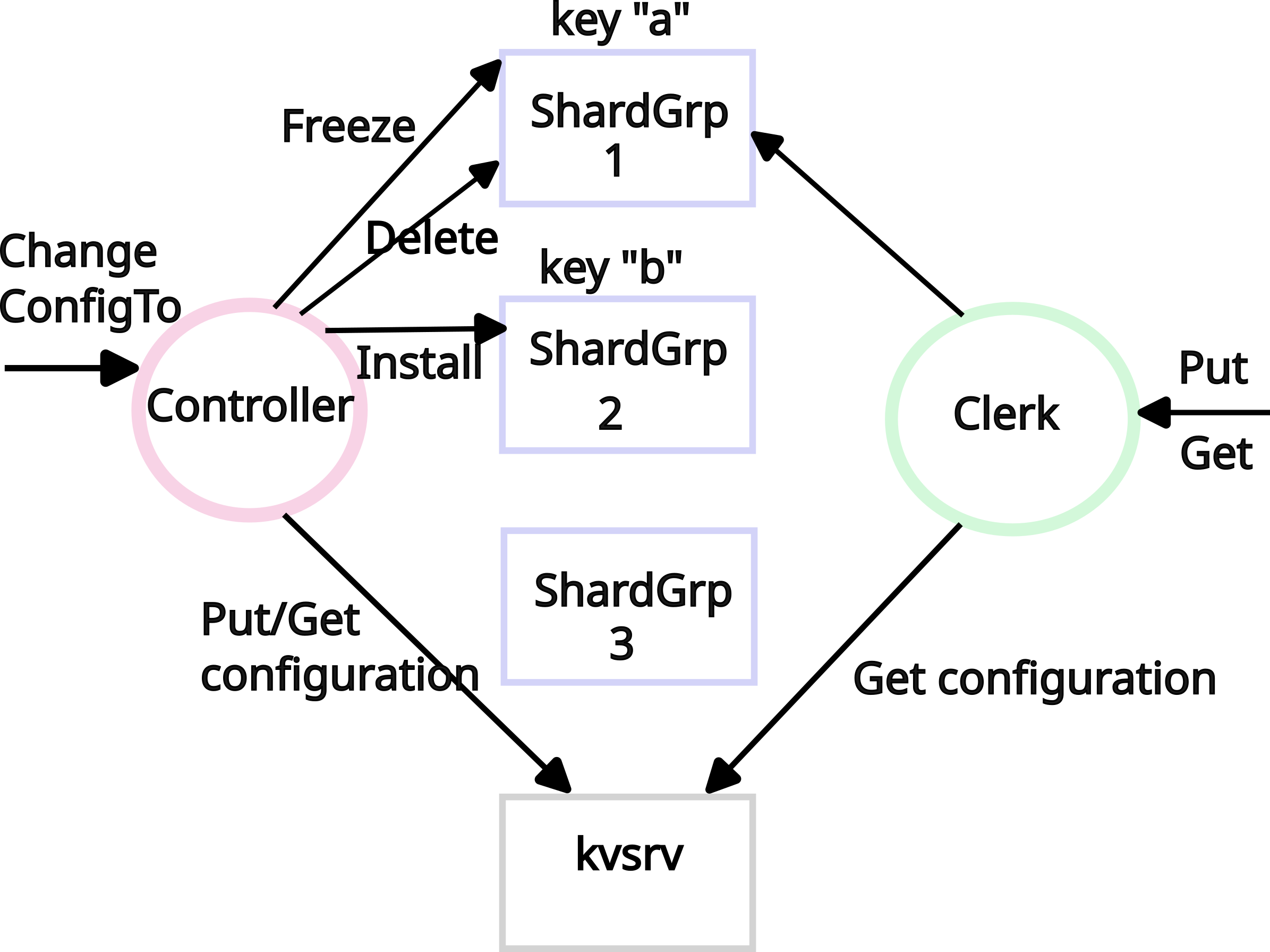
For dynamic sharding, I implemented a fault-tolerant shard controller (“shardmaster”) as another Raft-replicated service. A configuration is (Num, Shards[10] -> gid, Groups: map[gid][]servers). I replicate Join(gid->servers), Leave([]gid), Move(shard,gid), and Query(num) operations through Raft so that every controller instance applies them in the same order. Rebalancing after Join/Leave produces near-even shard counts—differing by at most one—by repeatedly moving shards from the most-loaded to the least-loaded groups with deterministic tie‑breaking (by gid) so all replicas compute the same result. Query returns either the latest configuration or the numbered configuration the client requested. Because the shardmaster runs on Raft, configuration changes are linearizable and survive crashes or partitions.
Each shard group (gid) is an independent KV-Raft cluster that tracks the current configuration number and a per‑shard state machine. Client requests are routed to the group responsible for keyShard(key); a server rejects stale or misrouted requests with ErrWrongGroup. When the shardmaster moves from config C to C+1, a background task in each group first Raft‑applies the new config as a barrier, then for every shard newly assigned to the group it pulls the shard state from the previous owner via an RPC like GetShard(shard, C), which returns the shard’s KV pairs plus the subset of the dedup table relevant to that shard.
The receiver proposes an InstallShard(shard, data, dedup, C) command to its own Raft; only when that command is committed do I mark the shard “Serving” for config C+1. After installation, the new owner sends a GCShard(shard, C) to the old group; the old group deletes its local copy only by Raft‑committing the GC command, preventing data loss on replays. All reconfiguration steps (Config, InstallShard, GCShard) and all client ops flow through Raft, so there is a single linear history per group even across migrations. The KV layer’s snapshotting remains enabled and includes shard metadata and dedup entries, which keeps recovery bounded while preserving exactly‑once semantics through moves and crashes.